Technical Details
1. Technical Overview
The SCTA system (or better SCTA ecosystem) is designed to break apart and modularize the independent and re-usable features of a traditional webstack. By separating the monolithic stack into independent pieces, we can reduce the need to needless recreate data, code libraries, or front-end clients. These pieces can be re-used, mixed, combined, and separated. This means by creating data and allowing it to be aggregated by the SCTA you are never siloing your data into one system, and you always remain free to continue doing whatever you like with that data. But it also means if data has already been created you don't need to re-create it. More importantly, because data is separated from any one particular technology stack, it can combined with other pieces of distributed data, allowing us to create a network of information that spans the entire corpus, again, all while refusing to silo any piece of data in any particular system.
This separation of concerns also helps to reduce the load of a traditional software stack. Instead of everyone having to create a new web stack to create a basic website to display data of interest, they can leverage professional grade code and software that have already been built and are maintained by the community. Likewise, code contributions or improvements that any one project makes to this open source software becomes an improvement that every project can make use of it.
The central separation of concerns that lies at the heart of the SCTA is visualized below:
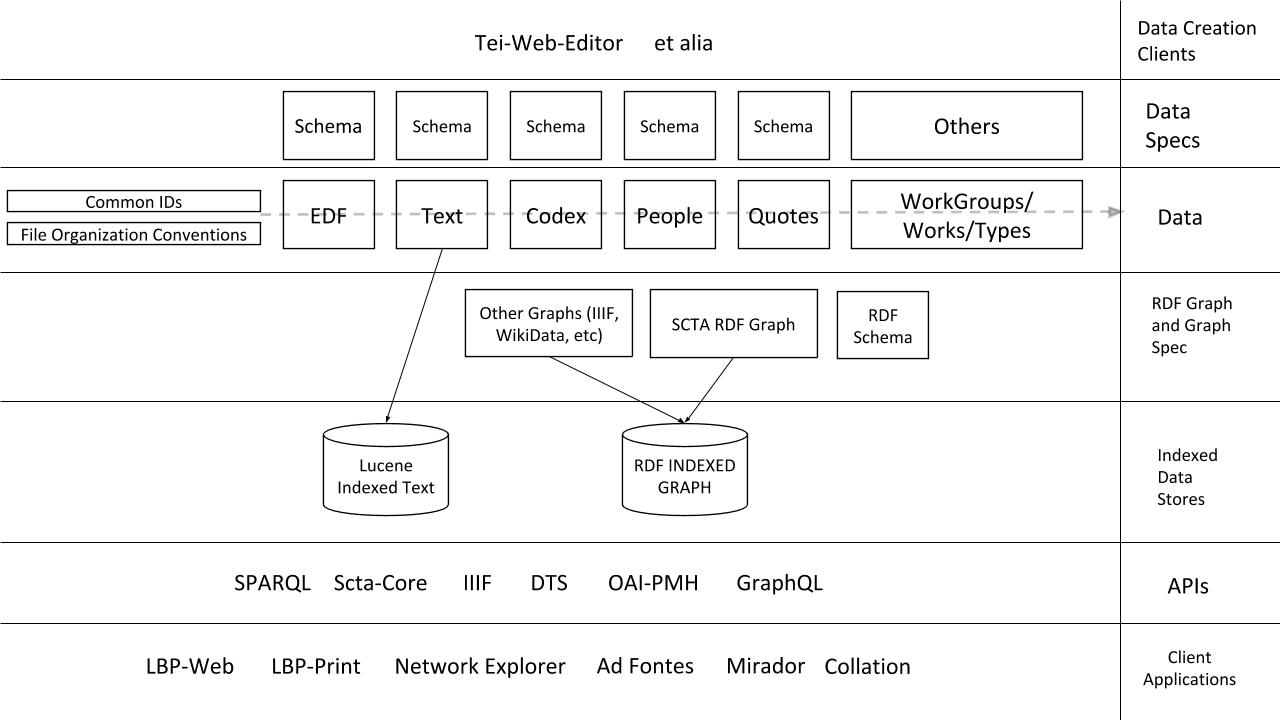
The various pieces of this visualization and the technical specifications that govern them are defined more precisely below:
2. Raw Data Creation Specifications
Data aggregation into a connected graph requires structured data.
Below are the data specification created by or adopted by the SCTA community
Expression Description Files (EDFs) | https://github.com/scta/edf-schema
Text Edition Schema: LombardPress-Schema | https://github.com/lombardpress/lombardpress-schema
Transcriptions Description File (TDFs) | https://github.com/scta/tdf-schema
People Description Files | In Development
Codex Description Files | In Development
3. The SCTA RDF Schema and RDF Aggregation
Aggregation of raw data requires a output specification for the resulting graph.
This specification is the SCTA RDF Schema | https://github.com/scta/scta-rdf-schema/
Using the raw data structured according to the above specifications an aggregator can combine that information to build a connected graph structure according to the SCTA-RDF Schema
The SCTA-RDF Aggregation Application | https://github.com/scta/scta-rdf is one such application.
4. APIs
Using the connected graph built by the SCTA Aggregation Application, API's can be built to facilitate the access and use of the SCTA graph
SCTA Core
http://scta.info/resource/scta
Description: Designed for basic navigation and exploration of the SCTA catalogue
Machine accessible via content negotiation
$ curl -iH "Accept: text/plain" http://scta.info/resource/lectio1
$ curl -iH "Accept: text/turtle" http://scta.info/resource/lectio1
$ curl -iH "Accept: application/rdf+xml" http://scta.info/resource/lectio1
$ curl -iH "Accept: application/json" http://scta.info/resource/lectio1
$ curl -iH "Accept: application/trix" http://scta.info/resource/lectio1
$ curl -iH "Accept: */*" http://scta.info/resource/lectio1
SCTA Sparql Endpoint
http://sparql.scta.info/ds/query
Description: A public sparql endpoint to which SPARQL queries can be sent via POST or GET using the ?query parameter.
SCTA Presentation (In development)
http://scta.info/api/presentation/1.0/[top-level-expression-short-id], e.g. https://scta.info/api/presentation/1.0/plaoulcommentary
Description: designed to facilitate easy representation of the SCTA catologue and texts in a client viewer. For a use case example, see the "Pellego" Application below.
IIIF
https://scta.info/iiif/scta/collection
https://scta.info/iiif/codices/collection
Description: A IIIF representation of the SCTA catalogue designed to faciliate use of SCTA texts and image connections within IIIF compatible viewers.
OAI-PMH
The OAI-PMH endpoint follows the OAI-PMH specification and allows for metadata harvestion of the SCTA catalogue by groups like Worldcat, et alia.
Distributed Text Services (In development)
https://scta.info/dts/collections
Description: A representation of the SCTA catalogue conforming the emerging specifications of the Distributed Text Services working group, designed to make the SCTA catalogue accessible via any DTS compliant client.
CSV API
Description: A API designed to facilitate text analysis. The API returns plain text results at the paragraph level alongside comma separated identifiers.
GraphQl (In development)
https://graphql.scta.info/graphiql
Description: A graphql based api, based on the idea of hypergraphql.
5. Known Implementations
Libraries
Lbp.rby (http://github.com/lombardpress.org/Lbp.rb): A ruby library for a exploring the SCTA Core API
Lbppy (http://github.com/lombardpress.org/lbppy): A python library for exploring the SCTA Core API
Lbp.js (https://github.com/lombardpress/lbp.js): A python library for exploring the SCTA Core API
Viewers
Lombardpress-Web (http://github.com/lombardpress.org/lombardpress-web): A client for viewing texts and images indexed in the SCTA. For a live instance, see http://scta.lombardpress.org
SCTA Mirador Instance (http://mirador.scta.info): An instance of the IIIF viewer, Mirador, customized to faciliate the exploration of the the SCTA catlogue through images and accompanying metadata.
Lombardpress-Print (http://github.com/lombardpress.org/lombardpress-web): A command line utility script for producing camera-ready print renderings of texts in the SCTA.
LombardPress-Print-Web-App: A website configured to use the LombardPress-Print CLI, and create typeset texts on-demand. It can also be used a service allowing other clients the ability to request typeset PDFs on demand.
Pellego: And minimalist javascript viewer, designed to use the SCTA Presentation API. Designed to be custom configured and used as a standalone web app or embedded in a website, see http://lombardpress.org/pellego/.
Ad Fontes: A Quotation Explorer App that allows users to explore the quotations and connected sources within the Scholastic Corpus.