With these APIs in place, we can re-use our connected data to build a plurality of applications to suit different research purposes.
Here are just a couple of independent applications using data provided by the SCTA.
We exist to resist the fragmenting tendencies of the traditional publication workflow and show scholars that there is another way: one that makes textual data freely available for use and re-use, that encourages collaboration instead of competition, and fights redundancy at all costs.
Are you editing or translating a text related to the scholastic tradition? Whether you're working on a critical edition, diplomatic edition, or translation, your work has a place in the SCTA. Resist the defunct workflow of for-profit proprietary publishers. Work with the SCTA community to get your text peer reviewed, published, and disseminated to the world.
Are you a digital humanist? Are you working on corpus analysis or natural language processing? Don't recreate data. Use our SPARQL endpoint and APIs to access SCTA data to build amazing applications and to analyze one of the largest digital archives of scholastic Latin in the world.
Today, the traditional mechanisms of publishing scholarly editions of scholastic texts are no longer helping to advance scholarship. Instead, traditional publishing workflows are preventing progress. They are preventing collaborative aggregation, computer assisted analysis and discovery, open access, and data re-use. The fragmentation of these editions with different publishers, who prepare data according to proprietary and incompatible data standards means (1) that the creation of an edition requires wasteful redundancy, and (2) the aggregation and analysis of connected content is impossible. This is the essence of a data silo.
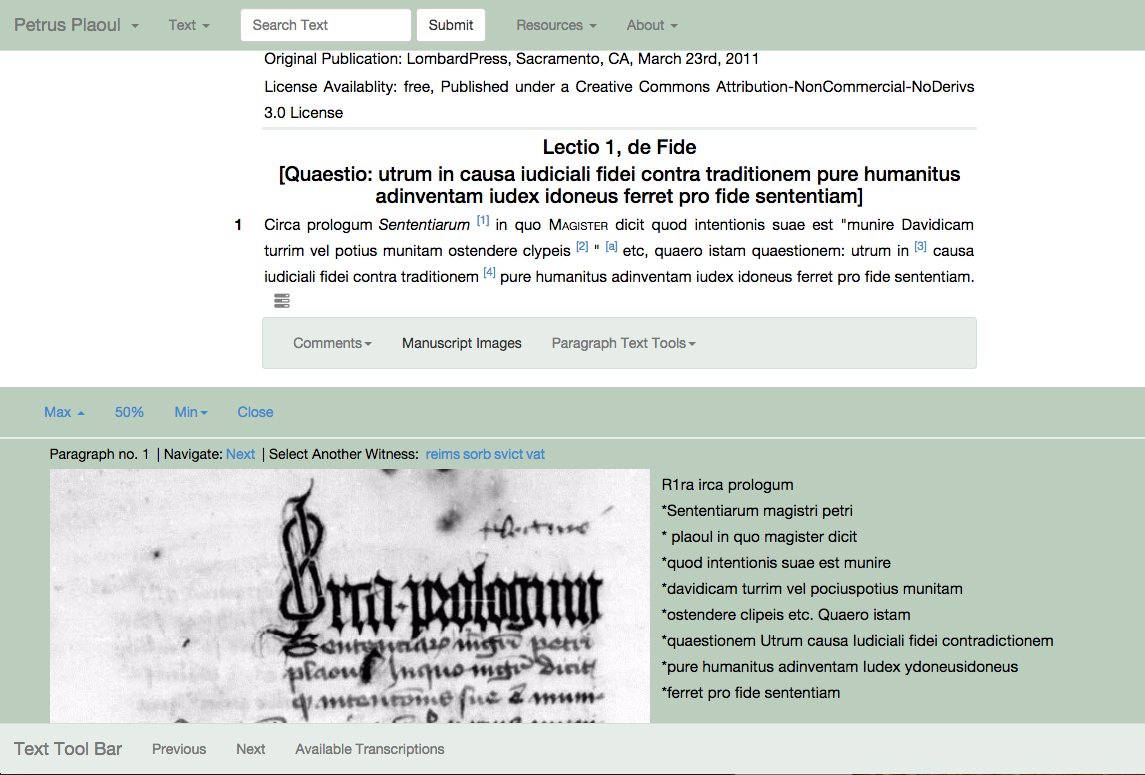
The SCTA community adopts, develops, and publishes standards for semantically encoding texts related to the scholastic tradition. When we, as a community, adopt these guidelines, our data becomes interoperable. For example, the SCTA supports specialized encoding schemas specifically tailored to scholastic texts. One example is the LombardPress Schema, which is a customization of the more general TEI Guidelines. If you're preparing a text, all you need to do is follow the LombardPress Schema and your text can be crawled and connected to the larger global network.
The SCTA build script crawls this interoperable data and builds a network graph. This graph documents connections within and between texts edited by different people all over the world. It also makes connections to other data sets around the world, helping to create a global graph of information. These connections enable us to discover new information about the corpus. The connections allows us to query for related texts at granular levels and even request the image of manuscript facsimiles of these texts published by libraries all over the world.
Once the graph is made, the SCTA makes this data available for use and re-use by other applications.
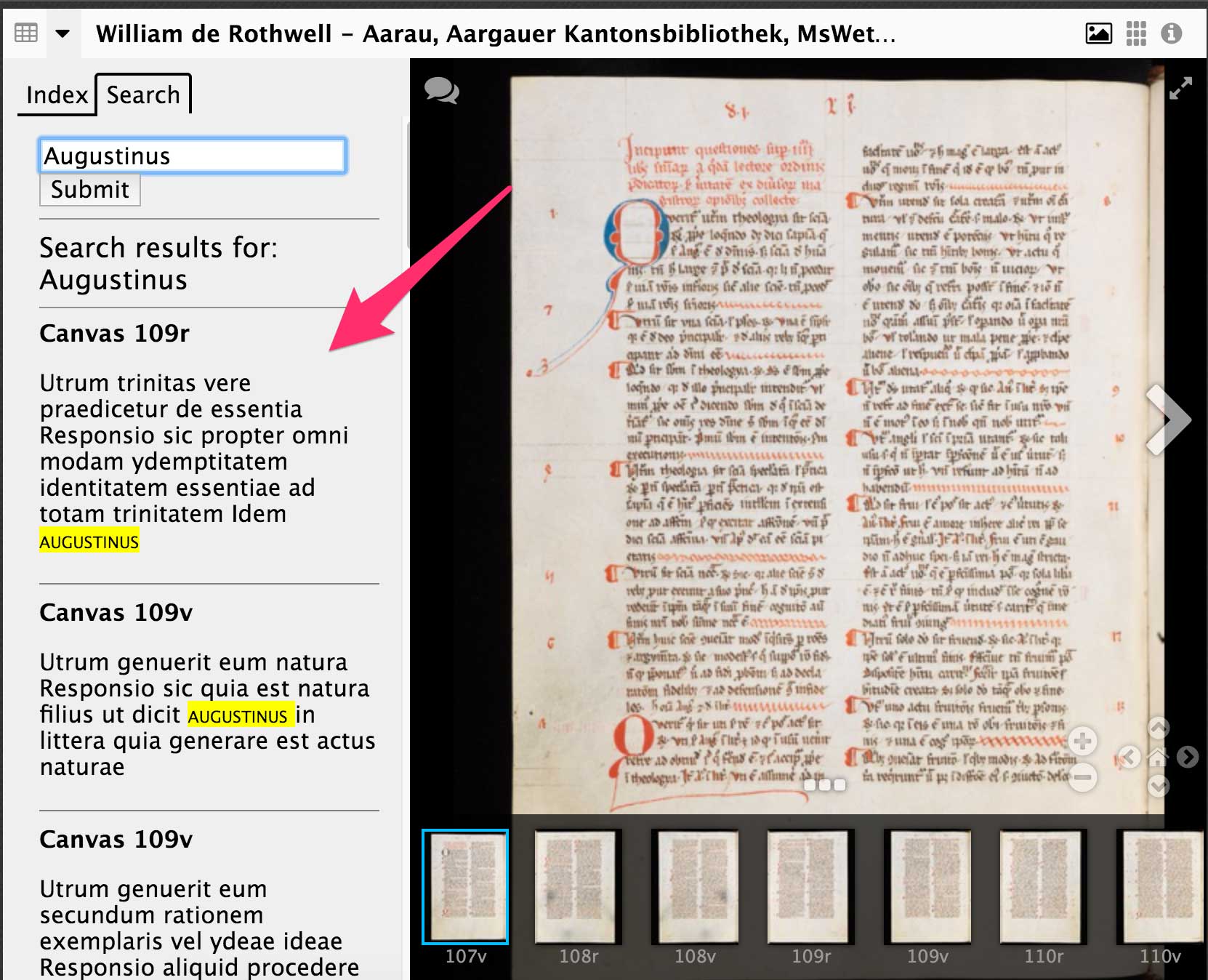
The SCTA maintains a public SPARQL endpoint, which means anyone can query the graph directly for the information they need. But we also publish the graph according to both custom in-house APIs and external APIs. For example, the SCTA publishes data related to manuscript images available via the IIIF presentation API. See http://scta.info/iiif/scta/collection. Using this API, any IIIF compliant viewer can display transcriptions, tables of contents, and other kinds of information alongside manuscript images.
With these APIs in place, we can re-use our connected data to build a plurality of applications to suit different research purposes.
Here are just a couple of independent applications using data provided by the SCTA.
The scholastic corpus — that is, the rich tradition of philosophy and theology spanning nearly 700 years from the 12th to the 18th century — understood in terms of its full depth and breadth is too big for any one scholar to ever read or absorb.
Nevertheless, it is highly interconnected and interdependent.
Thus, despite the fact that none of us can read the whole, the meaning of each argument is dependent on the whole. And our lack of access to the whole means our understanding of the parts will always be impoverished.
Nearly every text is dependent on a previous text or text tradition, whether as a commentary or revision or expansion or abbreviation. And nearly every text is itself a composition of an elaborate set of references and citations linking the corpus together.
The result of these various intertextual dependencies compounded over centuries is an amazing tapestry that, taken together, could show us the migration, mutation, and development of ideas bringing about the Renaissance and the Reformation, and leading directly to the Enlightenement and the Scientific Revolution.
The problem, again, is that the current publication paradigm makes it impossible for us to see this tapestry. If we are ever to see the whole, we must find a collaborative solution that allows the small contributions of individuals and editors to be aggregated over time into an organized and navigable network.
This is the aim of the Scholastic Commentaries and Texts Archive.
First: to form a community of people who have agreed upon editorial guidelines and best practices that in turn lay the foundation for the aggregation and organization of the collaboratively constructed network of scholastic texts.
Second: to actualize that aggregation and organization and offer that aggregated data as a service to the community for both the most traditional and untraditional re-uses of that textual data.
Here's are some places to get started:
We have a community page at http://community.scta.info. Here we post articles on how to get started, how to contribute, and general responses to frequently asked questions.
Jeffrey Witt maintains several articles about the SCTA on his project blog at http://lombardpress.org. These articles are usually speculative and experimental in nature, but they offer deep dives into the SCTA data structure and how it can be used by client applications like the LombardPress applications.
You can also join our slack channel and ask the community questions.